AI TOOL PROFILE
iomete: Self-Hosted Data Lakehouse Platform

- Data and Analytics
- Data Management
- Enterprise data teams
- Organizations with strict data residency requirements
- Technical teams experienced with Kubernetes
Pricing
Offers a Free Tier (up to 100 vCPUs). Paid tiers include an Enterprise Plan starting at $500 per vCPU per year (with a $100,000 minimum) and a Business Critical Plan with custom pricing (with a $250,000 minimum).
At a glance
- Best for
- Enterprise data teams, Organizations with strict data residency requirements, Technical teams experienced with Kubernetes
- Key use cases
- Maintaining Data Sovereignty, AI and ML Model Training, Real-time Operational Analytics, Hybrid Cloud Data Management
- Integrations
- Kafka, Amazon Kinesis, Apache Pulsar, JDBC, ODBC
- Official website
- Visit iomete official website
How AI is used
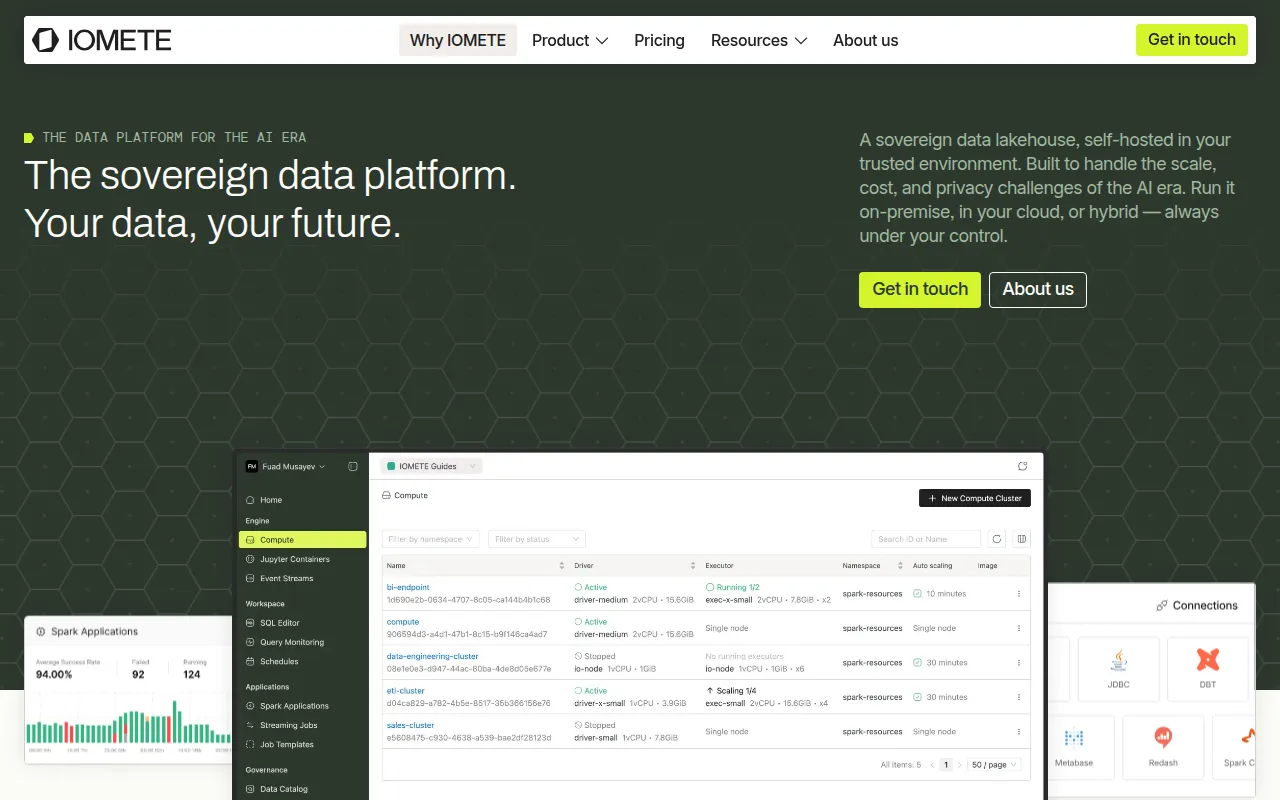
iomete is a data lakehouse platform built on Apache Iceberg and Apache Spark that runs on Kubernetes. Unlike typical SaaS data platforms, it is designed to be self-hosted, which supports deployment on-premises, in private clouds, public clouds, or hybrid environments. This architecture is designed to provide users with control over data residency and security.
The platform is intended for enterprise data teams managing large datasets for analytics and AI workloads. It includes tools for SQL querying, Spark job orchestration, and real-time data streaming to handle structured and unstructured data in one place.
Buyers should confirm their internal infrastructure capabilities, as the platform requires Kubernetes for deployment and management.
Key Features
Self-Hosted Architecture
Supports deployment on-premises, in private or public clouds, or hybrid setups via Kubernetes.
SQL Editor
A web-based environment for writing and executing queries with auto-completion and syntax highlighting.
Real-time Streaming
Supports ingesting and processing data streams from Kafka, Kinesis, and Pulsar.
Data Access Controls
Provides security management at the row and column level, including data masking.
ML Notebooks
Integrated interactive environments supporting Python, R, and Scala for machine learning workflows.
Data Catalog
A central repository for managing metadata, tracking lineage, and discovering data assets.
Use Cases
Maintaining Data Sovereignty
Hosting data within a company's own trust perimeter to help meet GDPR, HIPAA, or SOC2 compliance requirements.
AI and ML Model Training
Using the lakehouse and ML notebooks to prepare datasets and train models on local or hybrid infrastructure.
Real-time Operational Analytics
Streaming data from Kafka or Kinesis into Iceberg tables for SQL-based analysis.
Hybrid Cloud Data Management
Deploying clusters across multiple regions or combining on-premises data centers with public cloud resources.
Integrations
- Kafka
- Amazon Kinesis
- Apache Pulsar
- JDBC
- ODBC
- dbt-spark adapter
FAQ
What is the difference between iomete and a standard SaaS data warehouse?
- Unlike SaaS platforms, iomete is self-hosted in the customer's own infrastructure. This is designed to provide more control over data location, help prevent vendor lock-in, and allow the use of existing cloud discounts.
Where can iomete be deployed?
- It can be deployed on-premises, in private clouds, public clouds (such as AWS, Azure, and Google Cloud), or in a hybrid configuration using Kubernetes.
Does iomete have a free version?
- Yes, iomete offers a Free Tier that includes core features and supports up to 100 vCPUs.
Source category: Data & Analytics
Source subcategory: Data Management
More tools in Data & Analytics
Other published listings in the Data & Analytics category.
More tools in the Data Management software type
Related listings that share the same software type for comparison and shortlisting.